Hai semuanya, apa kabar? Mungkin teman-teman yang sering baca tulisan saya udah tau kalo saya dulu pernah nulis tentang High Availability (HA) di blog ini. Kali ini saya mau uji coba konfigurasi HA pada VM yang menggunakan Ceph storage. Intinya sih sama saja dengan apabila VM menggunakan shared storage lain seperti NFS. Tapi sekalian testing Ceph storage-nya juga hehehe.
Seperti beberapa tulisan sebelumnya, VM yang akan saya jadikan percobaan adalah VM AlmaLinux. Saat ini masih terdapat pada pve2. Konfigurasi HA ini dilakukan per VM. Konfigurasi dapat dilakukan melalui menu Datacenter > HA (gambar 1).
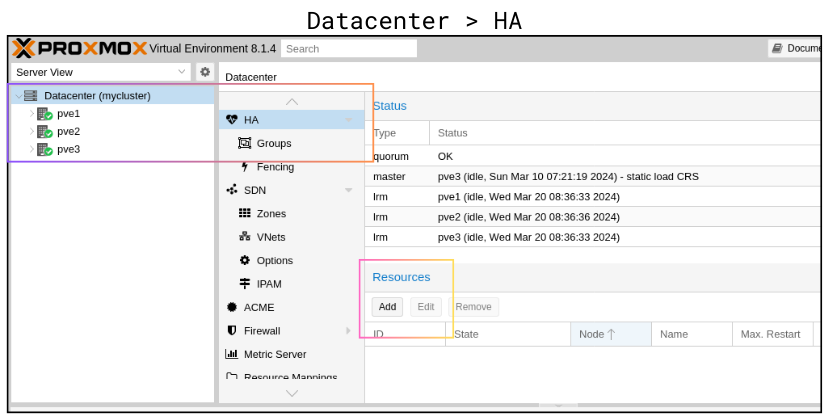
gambar 1
Pada gambar 1 juga ditandai pada bagian Resources. Untuk menambahkan/melakukan konfigurasi HA untuk VM, pilih tombol Add kemudian pilih VM yang akan dikonfigurasi HA-nya (gambar 2).
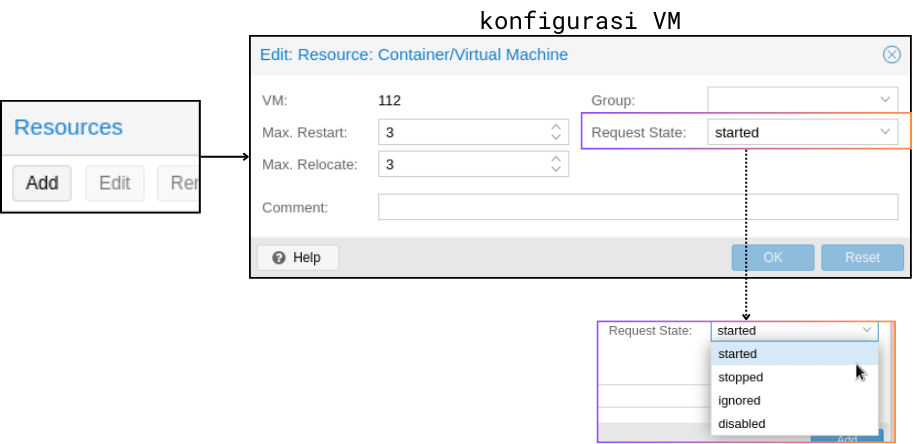
gambar 2
Gambar 2 menampilkan jendela konfigurasi HA. Pilih VM yang ingin kita konfigurasi pada parameter VM. Kemudian ada parameter lain seperti Max Restart, Max Relocate, dan Request State. Parameter Max Restart digunakan untuk menentukan berapa kali Proxmox VE akan mencoba memulai ulang VM pada node saat terdeteksi kegagalan. Parameter Max Relocate digunakan untuk menentukan berapa kali Proxmox VE akan memindahkan VM ke node lain. Nilai default dari kedua parameter tersebut adalah 1. Kemudian ada juga parameter Request State untuk menentukan keadaan VM setelah berhasil dipindahkan. Pengujian yang dilakukan menggunakan konfigurasi yang ada pada gambar 2 (Max Restart&Relocate=3, State=Started). Tekan OK apabila konfigurasi telah sesuai. Apabila berhasil, VM tersebut akan muncul pada halaman Datacenter>HA (seperti pada gambar 3).
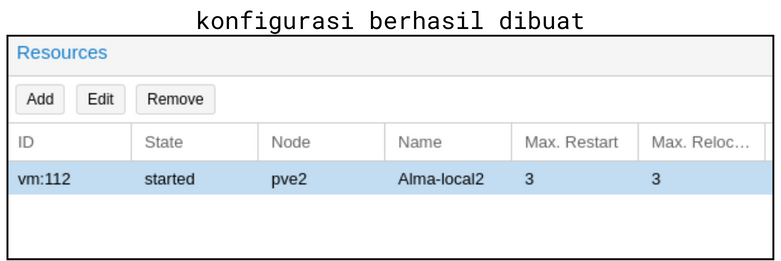
gambar 3
HA ini dapat diterapkan pada VM yang dirasa penting dan “harus” selalu tersedia. Saya akan coba lakukan pengujian dengan menonaktifkan koneksi (cabut kabel ethernet menuju node pve1) dan kita lihat seberapa lama proses migrasi otomatis oleh HA bekerja. Kita lihat video dibawah (proses migrasi secara otomatis).
video 1
Pada pengujian yang dilakukan, saya cabut kabel ethernet pada pukul 10:22. Beberapa saat kemudian pve2 terdeteksi down di web interface. Saya cek lagi VM masih belum pindah, mungkin masih melakukan restart sesuai dengan parameter yang ada pada gambar 2. Kemudian saya cek pada Datacenter>HA, VM sedang dalam proses fencing. Fencing adalah mekanisme yang menjaga agar VM hanya berjalan pada satu node dalam waktu yang sama. Kemudian, VM mulai pindah ke node pve3 dan status pada Datacenter>HA menjadi started. Proses ini (hingga VM dinyalakan kembali) membutuhkan waktu sekitar 4 menit dalam pengujian kali ini.
Itu dulu tulisan kali ini. Sampai jumpa, bye~